How we built a global ML model with Google Earth Engine
A couple posts ago, I described the machine learning model that we developed to predict the extent of cropland irrigation worldwide. This post is a collection of all the things I learned about Google Earth Engine that went into running a global-scale model successfully.
The importance of selection effect
It was the first class of a data science course in the MIDS program. Our instructor started off with a question: “Do you think this academic program gives you a better career?” We gave a bunch of answers, quite the ignorant folks that we were. Of course, is this even a question at this point?! Yes, here are all the new things we’re learning. Yes, the instructors are top-notch. Yes, look at the syllabus and the projects, yada yada … nothing surprising there.
The instructor asked, “Yes, but how do you know that the program is making you better? What if you joined the program because you were motivated enough to apply and work through it, and therefore you’d get better in your career anyway?”
Global Irrigation Map, our capstone machine learning project
For our capstone project at UC Berkeley, we worked with the Department of Environmental Studies. We developed a machine learning model that we continued to improve even after the course term, and I’m happy to report that it is now under discussion to be a published paper – a first for the program itself, according to our lecturer.
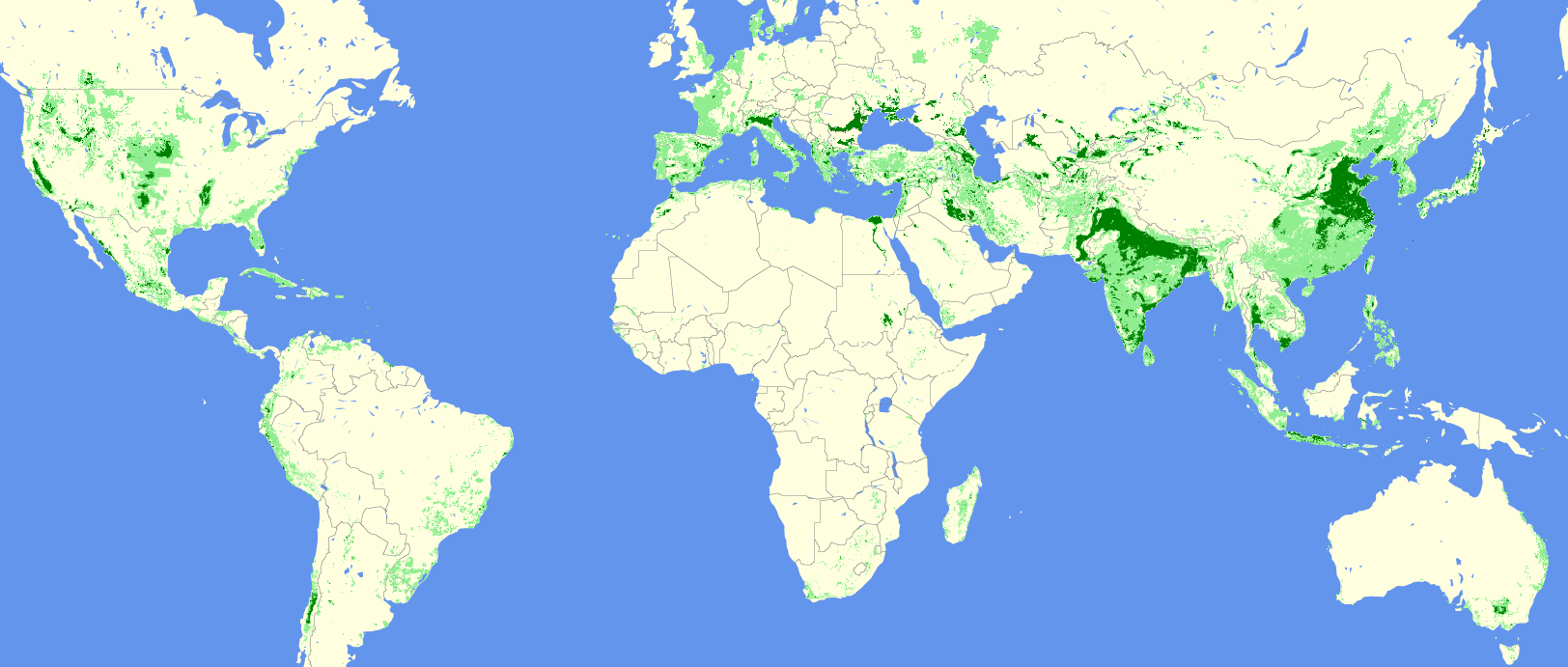
Update Aug/5/2020: New blog post: a behind the scenes look on how we built the model.
Lazy evaluation in real life
There are so many great ideas in engineering we can take home and apply to our own lives. Today I will talk about one of them: lazy evaluation.
How are you saving your knowledge?
We live in a “knowledge economy”. Every day brings with it new information. Do you have an external system to store your knowledge efficiently and effectively?
Notes on Spark Streaming app development
This post contains various notes from the second half of this year. It was a lot of learning trying to get a streaming model working and ready in production. We used Spark Structured Streaming, and wrote the code in Scala. Our model was stateful. Our source and sink were both Kafka.
The Spark tunable that gave me 8X speedup
There are many configuration tunables in Spark. However, if you have time for only one, set this one. It made a streaming application we run process data 8X faster. That’s 800% improvement, no code change needed!
Privacy in today's age with a SOCKS proxy
Say you are at a cafe, and you want to surf the Web. But the WiFi is not secure. Or say your company lets you bring your laptop, but what if its firewall has blocked your favorite website? Is there no hope, besides paying $15 to a VPN provider?
There is, and it costs about $3.50 per month as of this writing.
Getting top-N elements in Spark
The documentation for pyspark top() function has this warning:
This method should only be used if the resulting array is expected
to be small, as all the data is loaded into the driver's memory.
This piqued my interest: why would you need to bring all the data to the driver, if all you need is a few top elements?
The answer is: it does not load all the data into the driver’s memory.
Livy is out of memory
Spark jobs were failing. All of them. The data pipeline had stopped. This is a tale of high-pressure debugging.
Accessing home computer from anywhere
Do you sometimes want to access your home computer from an outside network? Maybe you use another system, but you do not trust it and would prefer your home computer for some workflows?
This post outlines the steps to make such access possible.
The program that would not go away
This post is about a program hang. The hang was in the Python process that was running Ansible scripts. The problem was hard to debug and had me go back to Unix textbook.
Correct way to create a directory in Python
Can you see the problem with this code? It comes from Ansible, v2.1.1.0.
if not os.path.exists(value):
os.makedirs(value, 0o700)It’s quite straightforward. It checks if a directory path exists. If
it does not, then it creates the directory path, similar to mkdir
-p. What could be wrong?
Getting rid of unused virtual disks on XenServer
A continuous test server I’d set up had stopped working. The XenServer on which it was running had a 1TB disk: and it was full. What’s going on?
Log rotation, no code change needed
This post shows you how to rotate old logs from your application. There is no change to application code. There is no specialized logging library or framework needed. It works for any language, on standard Unix platform.
Resetting a TCP connection and SO_LINGER
Can you quickly close a TCP connection in your program by sending a reset (“RST”) packet?
Program crashes, only in 64-bit mode
This is a story of a program that worked, until it broke on a 64-bit platform.
ps | grep is broken on FreeBSD
It is true. Even on the latest FreeBSD 11.0 (I checked the source tree).
Debugging emacs slowness
I use Emacs (emerge) while merging files. Today, when trying to merge some Python code, I found that it was taking exceedingly long time. It was blank for 5 minutes and counting.
Weird PID Files
This is a story of multiple processes running on a system, but with empty PID files.
It took a lot of debugging.
Don't hang up on me
Can you tell me when a shell sends a “HANGUP” signal to a process? What happens if there is a pipeline? What if you prefix this pipeline with the “nohup” command?
Rotating the log makes it empty
If you don’t do log rotation right, you may have a full hard drive and a ghost file.
Socket timeout
Have you run into a problem that happens only once in a while, and you never seem to have enough information to figure it out? We all have. This is one such tale: except that it has a happier ending.
Build fails, only for you
As programmers, we face it many times: a build fails on only our system. This is one such tale.
You got too many open files
This is a tale about a hopelessly bad error message.